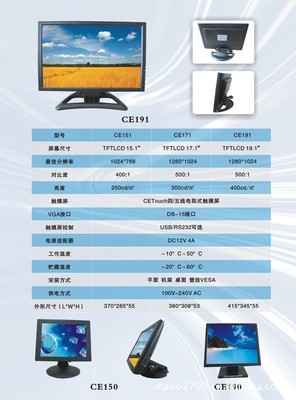
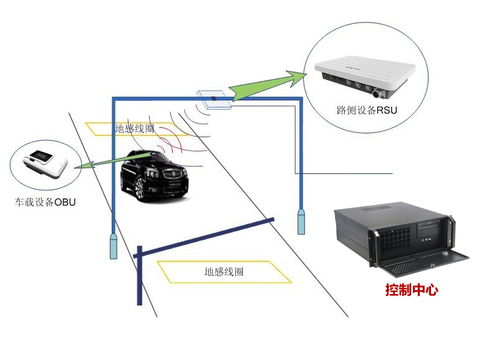
工控電腦產品
Product
Information
公司名稱:海口皇凱網絡科技有限公司
法人代表:康健
注冊地址:海南省海口市龍華區秀英村289號202房
所屬行業:軟件和信息技術服務業
更多行業:其他未列明信息技術服務業,其他信息技術服務業,軟件和信息技術服務業,信息傳輸、軟件和信息技術服務業
經營范圍:信息科技技術服務,網絡技術服務,廣告設計、制作、代理、發布。